文章列表
-
- Python scrapy爬取小說代碼案例詳解
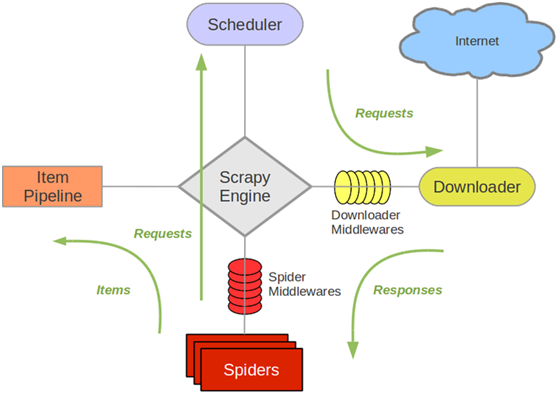
- scrapy是目前python使用的最廣泛的爬蟲框架架構圖如下解釋: Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、數據傳遞等。 Scheduler(調度器): 它負責接受引擎發送過來的Request請...
- 日期:2022-07-18
- 瀏覽:42

-
- python中scrapy處理項目數據的實例分析
- 在我們處理完數據后,習慣把它放在原有的位置,但是這樣也會出現一定的隱患。如果因為新數據的加入或者其他種種原因,當我們再次想要啟用這個文件的時候,小伙伴們就會開始著急卻怎么也翻不出來,似乎也沒有其他更好的搜集辦法,而重新進行數據整理顯然是不現實的。下面我們就一起看看python爬蟲中scrapy處理項...
- 日期:2022-07-04
- 瀏覽:163

-
- python爬蟲scrapy框架之增量式爬蟲的示例代碼
- scrapy框架之增量式爬蟲一 、增量式爬蟲什么時候使用增量式爬蟲:增量式爬蟲:需求 當我們瀏覽一些網站會發現,某些網站定時的會在原有的基礎上更新一些新的數據。如一些電影網站會實時更新最近熱門的電影。那么,當我們在爬蟲的過程中遇到這些情況時,我們是不是應該定期的更新程序以爬取到更新的新數據?那么,增...
- 日期:2022-06-27
- 瀏覽:6

-
- Python中scrapy下載保存圖片的示例
- 在日常爬蟲練習中,我們爬取到的數據需要進行保存操作,在scrapy中我們可以使用ImagesPipeline這個類來進行相關操作,這個類是scrapy已經封裝好的了,我們直接拿來用即可。 在使用ImagesPipeline下載圖片數...
- 日期:2022-06-14
- 瀏覽:35
-
- Python爬蟲基礎講解之scrapy框架
- 網絡爬蟲網絡爬蟲是指在互聯網上自動爬取網站內容信息的程序,也被稱作網絡蜘蛛或網絡機器人。大型的爬蟲程序被廣泛應用于搜索引擎、數據挖掘等領域,個人用戶或企業也可以利用爬蟲收集對自身有價值的數據。一個網絡爬蟲程序的基本執行流程可以總結三個過程:請求數據,解析數據,保存數據數據請求請求的數據除了普通的HT...
- 日期:2022-06-16
- 瀏覽:80
-
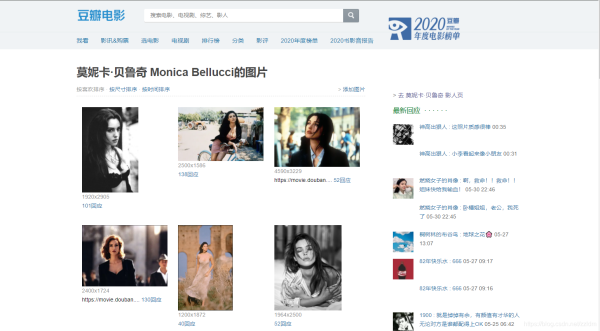
- Python爬蟲實戰之使用Scrapy爬取豆瓣圖片
- 使用Scrapy爬取豆瓣某影星的所有個人圖片以莫妮卡·貝魯奇為例1.首先我們在命令行進入到我們要創建的目錄,輸入 scrapy startproject banciyuan 創建scrapy項目創建的項目結構如下2.為了方便使用pycharm執行scrapy項目,新建main.pyfrom scra...
- 日期:2022-06-14
- 瀏覽:141
-
- Django結合使用Scrapy爬取數據入庫的方法示例
- 在django項目根目錄位置創建scrapy項目,django_12是django項目,ABCkg是scrapy爬蟲項目,app1是django的子應用2.在Scrapy的settings.py中加入以下代碼import osimport syssys.path.append(os.path.dir...
- 日期:2024-09-11
- 瀏覽:14
- 標簽: Django
-
- 詳解Python的爬蟲框架 Scrapy
- 網絡爬蟲,是在網上進行數據抓取的程序,使用它能夠抓取特定網頁的HTML數據。雖然我們利用一些庫開發一個爬蟲程序,但是使用框架可以大大提高效率,縮短開發時間。Scrapy是一個使用Python編寫的,輕量級的,簡單輕巧,并且使用起來非常的方便。一、概述下圖顯示了Scrapy的大體架構,其中包含了它的主...
- 日期:2022-07-15
- 瀏覽:3
-
- python中用Scrapy實現定時爬蟲的實例講解
- 一般網站發布信息會在具體實現范圍內發布,我們在進行網絡爬蟲的過程中,可以通過設置定時爬蟲,定時的爬取網站的內容。使用python爬蟲框架Scrapy框架可以實現定時爬蟲,而且可以根據我們的時間需求,方便的修改定時的時間。1、Scrapy介紹Scrapy是python的爬蟲框架,用于抓取web站點并從...
- 日期:2022-06-29
- 瀏覽:27
-
- python實現scrapy爬蟲每天定時抓取數據的示例代碼
- 1. 前言。1.1. 需求背景。 每天抓取的是同一份商品的數據,用來做趨勢分析。 要求每天都需要抓一份,也僅限抓取一份數據。 但是整個爬取數據的過程在時間上并不確定,受本地網絡,代理速度,抓取數據量有關,一般情況下在20小時左右,極少情況下會超過24小時。1.2. 實現功能。通過以下三步,保證...
- 日期:2022-06-29
- 瀏覽:3
 網公網安備
網公網安備