MySQL索引是啥?不懂就問(wèn)
以下是需要?jiǎng)?chuàng)建索引的常見(jiàn)場(chǎng)景,為了對(duì)比,創(chuàng)建測(cè)試表(a帶索引、d無(wú)索引):
mysql> create table test( --創(chuàng)建測(cè)試表 -> id int(10) not null AUTO_INCREMENT, -> a int(10) default null, -> b int(10) default null, -> c int(10) default null, -> d int(10) default null, -> primary key(id), --主鍵索引 -> key idx_a(a), --輔助索引 -> key idx_b_c(b,c) --聯(lián)合索引 -> )engine=InnoDB charset=utf8mb4;Query OK, 0 rows affected, 5 warnings (0.09 sec)mysql> drop procedure if exists insert_test_data;Query OK, 0 rows affected, 1 warning (0.00 sec)mysql> delimiter | --創(chuàng)建存儲(chǔ)過(guò)程,插入十萬(wàn)個(gè)數(shù)據(jù)mysql> create procedure insert_test_data() -> begin -> declare i int; -> set i=1; -> while(i<=100000) do -> insert into test(a,b,c,d)values(i,i,i,i); -> set i=i+1; -> end while; -> end |Query OK, 0 rows affected (0.11 sec)mysql> delimiter ;mysql> call insert_test_data(); --執(zhí)行存儲(chǔ)過(guò)程Query OK, 1 row affected (11 min 44.13 sec)
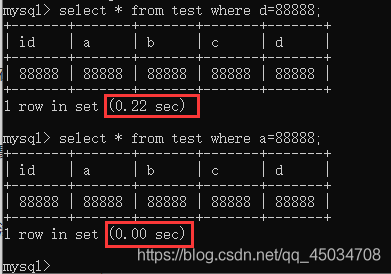
數(shù)據(jù)檢索時(shí)在條件字段添加索引
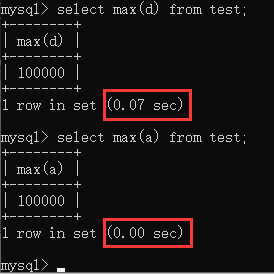
聚合函數(shù)對(duì)聚合字段添加索引
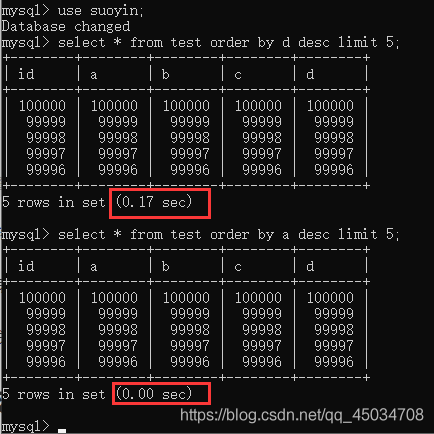
對(duì)排序字段添加索引
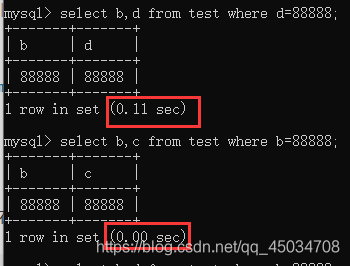
為了防止回表添加索引
關(guān)聯(lián)查詢(xún)?cè)陉P(guān)聯(lián)字段添加索引
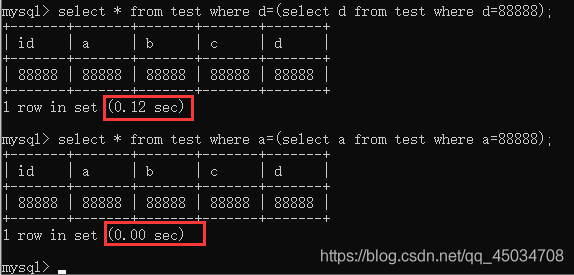
可以看出使用索引后,對(duì)查詢(xún)速度優(yōu)化提升是巨大的,本文將從底層到實(shí)踐搞懂MySQL索引。
從二叉樹(shù)到B+樹(shù)二叉樹(shù):
二叉樹(shù)(Binary Tree)是指至多只有兩個(gè)子節(jié)點(diǎn)的樹(shù)形數(shù)據(jù)結(jié)構(gòu),沒(méi)有父節(jié)點(diǎn)的節(jié)點(diǎn)為根節(jié)點(diǎn),沒(méi)有子節(jié)點(diǎn)的節(jié)點(diǎn)稱(chēng)為葉子節(jié)點(diǎn)。
二叉搜索樹(shù)就是任何節(jié)點(diǎn)的左子節(jié)點(diǎn)小于當(dāng)前節(jié)點(diǎn)鍵值,右子節(jié)點(diǎn)大于當(dāng)前節(jié)點(diǎn)鍵值。
如下圖的二叉搜索樹(shù),我們最多只需要 ⌈ l o g ( n ) ⌉ ⌈log(n)⌉ ⌈log(n)⌉即三次即可匹配到數(shù)據(jù),而線性查找的話(huà)最壞情況需要 n n n次才可匹配到。
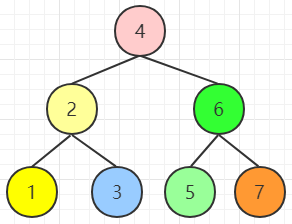
但是二叉樹(shù)可能會(huì)退化成鏈表的情況,如下圖所示,這樣就相當(dāng)于全部掃描了,導(dǎo)致效率不高,為了解決這個(gè)問(wèn)題,需要確保二叉樹(shù)一直保持平衡,即平衡二叉樹(shù)。
平衡二叉樹(shù):
平衡二叉樹(shù)(AVL樹(shù))在滿(mǎn)足二叉樹(shù)特性的基礎(chǔ)上,要求每一個(gè)節(jié)點(diǎn)的左右子樹(shù)高度差不能超過(guò)1。它保證了樹(shù)構(gòu)造的一個(gè)平衡,當(dāng)插入或刪除數(shù)據(jù)導(dǎo)致不平衡時(shí),會(huì)進(jìn)行節(jié)點(diǎn)調(diào)整來(lái)保持平衡(具體算法略),確保查找效率。
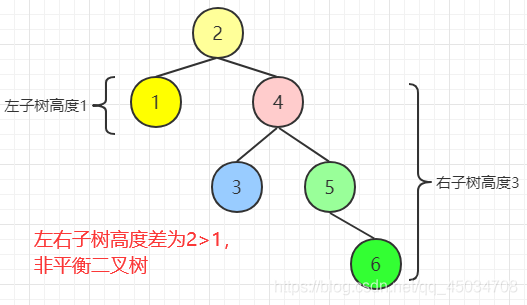
平衡二叉樹(shù)的一個(gè)節(jié)點(diǎn)對(duì)應(yīng)一個(gè)鍵值和數(shù)據(jù),我們每次查找數(shù)據(jù)就需要從磁盤(pán)中讀取一個(gè)節(jié)點(diǎn),也就是我們說(shuō)的磁盤(pán)塊,一個(gè)節(jié)點(diǎn)對(duì)應(yīng)一個(gè)磁盤(pán)塊。當(dāng)存儲(chǔ)海量數(shù)據(jù)時(shí),樹(shù)的節(jié)點(diǎn)會(huì)非常多,會(huì)進(jìn)行很多次的磁盤(pán)I/O,查找效率仍是極低的。這就需要一個(gè)單節(jié)點(diǎn)能存儲(chǔ)多個(gè)鍵值和數(shù)據(jù)的一種平衡樹(shù)了。
B樹(shù): B樹(shù)(Blance Tree)就是可以單節(jié)點(diǎn)存儲(chǔ)多鍵值和數(shù)據(jù)的平衡樹(shù),每一個(gè)節(jié)點(diǎn)我們稱(chēng)之為頁(yè)(Page),即一頁(yè)數(shù)據(jù)。每個(gè)節(jié)點(diǎn)存儲(chǔ)了更多鍵值和數(shù)據(jù),把鍵值和數(shù)據(jù)都放在一個(gè)頁(yè)當(dāng)中,并且每個(gè)節(jié)點(diǎn)擁有了更多子節(jié)點(diǎn),子節(jié)點(diǎn)的個(gè)數(shù)一般稱(chēng)為階。B樹(shù)在查找數(shù)據(jù)讀取磁盤(pán)的次數(shù)也就大大減少,查找效率比AVL高很多。
如下圖的3階B樹(shù)中,查找id=42的數(shù)據(jù)。首先在第一頁(yè)里判斷42鍵值大于39,根據(jù)指針P3找到第4頁(yè),再進(jìn)行比較,小于鍵值45,又根據(jù)指針P1找到第9頁(yè),發(fā)現(xiàn)匹配有匹配的鍵值42,即找到相應(yīng)數(shù)據(jù)。
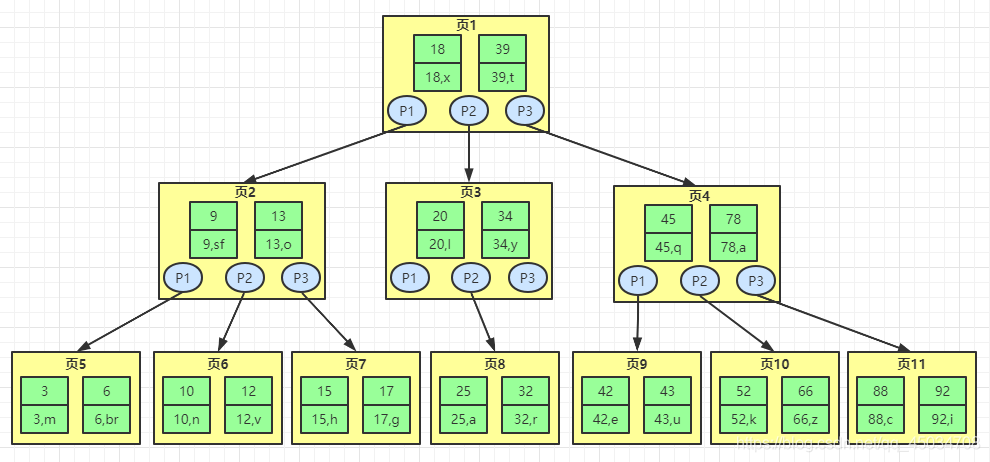
B+樹(shù):
B+樹(shù)是對(duì)B樹(shù)的進(jìn)一步優(yōu)化。簡(jiǎn)單說(shuō)就是B+樹(shù)的非葉子節(jié)點(diǎn)是不存儲(chǔ)數(shù)據(jù)的,僅存放鍵值。之所以這樣做,是因?yàn)閿?shù)據(jù)庫(kù)中頁(yè)的大小是固定的(InnoDB默認(rèn)16KB),如果不存儲(chǔ)數(shù)據(jù),就可以存儲(chǔ)更多鍵值,節(jié)點(diǎn)個(gè)數(shù)就越大,查找數(shù)據(jù)進(jìn)行磁盤(pán)I/O次數(shù)進(jìn)一步減少。
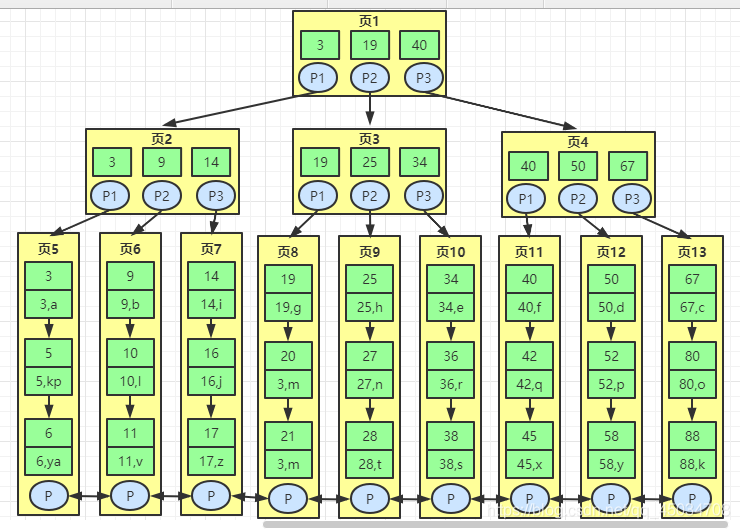
另外B+樹(shù)的階數(shù)是等于它的鍵值數(shù)量的,如果一個(gè)節(jié)點(diǎn)存儲(chǔ)1000鍵值的話(huà),那么只需要三層就可存儲(chǔ)10億數(shù)據(jù),所以一般查找10億數(shù)據(jù)只需兩次磁盤(pán)I/O即可(妙啊)。
同時(shí)B+樹(shù)葉節(jié)點(diǎn)的數(shù)據(jù)是按順序進(jìn)行排列的,所以B+樹(shù)適合范圍查找、排序查找和分組查找等(B各數(shù)據(jù)分散在節(jié)點(diǎn)上,相對(duì)就困難),也就是為什么MySQL采用B+樹(shù)索引的原因了。
聚集索引聚集索引或聚簇索引(Clustered Index)是一種對(duì)磁盤(pán)上實(shí)際數(shù)據(jù)重新組織并按指定的一個(gè)或多個(gè)列的值排序。數(shù)據(jù)行的物理順序與列值(一般是主鍵那列)的邏輯順序相同,一個(gè)表中只能有一個(gè)聚集索引(因?yàn)橹荒芤砸环N物理順序存放)。
InnoDB就是用的聚集索引,它的表中的數(shù)據(jù)都會(huì)有一個(gè)主鍵,即使你不創(chuàng)建主鍵,InnoDB會(huì)選取一個(gè)Unique鍵作為主鍵,如果表中連Unique鍵都沒(méi)有定義的話(huà),InnoDB會(huì)為表添加一個(gè)名為row_id的隱藏列作為主鍵。
也就是說(shuō)我們通過(guò)InnoDB把數(shù)據(jù)存放到B+樹(shù)中,而B(niǎo)+樹(shù)中的鍵值就是主鍵,那么在B+樹(shù)中的葉子節(jié)點(diǎn)存儲(chǔ)的就是表中的所有數(shù)據(jù)(即該主鍵對(duì)應(yīng)的整行數(shù)據(jù)),數(shù)據(jù)文件和索引文件是同一個(gè)文件,找到了索引便找到了數(shù)據(jù),所以我們稱(chēng)之為聚集索引。
聚集索引更新代價(jià)高。插入新行或更新主鍵時(shí)會(huì)強(qiáng)制將每個(gè)被更新的行移動(dòng)到新的位置(因?yàn)橐粗麈I排序),而移動(dòng)行可能還會(huì)面臨頁(yè)分裂問(wèn)題(即頁(yè)已滿(mǎn)),存儲(chǔ)引擎會(huì)將該頁(yè)分裂成兩個(gè)頁(yè)面來(lái)容納,頁(yè)分裂會(huì)占用更多磁盤(pán)空間。即索引重排,造成資源浪費(fèi)。
聚集索引適合范圍查詢(xún)。聚集索引查詢(xún)速度很快,特別適合范圍檢查(between、<、<=、>、>=)或group by、order by的查詢(xún)。因?yàn)榫奂饕业桨谝粋€(gè)值的行后,后續(xù)索引值的行在物理上毗連在一起而不必進(jìn)一步搜索,避免大范圍掃描,大大提高查詢(xún)速度。
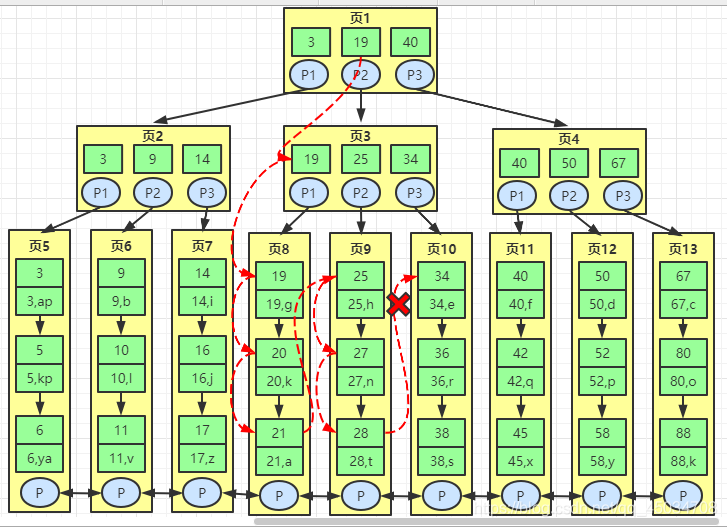
比如查詢(xún)id>=19并且id<30的數(shù)據(jù):通常根節(jié)點(diǎn)常駐在內(nèi)存中(即頁(yè)1已在內(nèi)存),首先在頁(yè)1找到了鍵值19及其對(duì)應(yīng)指針P2,通過(guò)P2讀頁(yè)3(此時(shí)頁(yè)3不在內(nèi)存中,需要從磁盤(pán)中加載),然后在頁(yè)3查找鍵值19的指針P1,又定位到頁(yè)8(同樣的從磁盤(pán)加載到內(nèi)存),因?yàn)閿?shù)據(jù)是按鏈表進(jìn)行順序鏈接的,可以通過(guò)二分找到鍵值19對(duì)應(yīng)數(shù)據(jù)。
找到鍵值19后,因?yàn)槭欠秶檎遥@時(shí)可以在葉子節(jié)點(diǎn)里進(jìn)行鏈表的查詢(xún),依次遍歷并匹配滿(mǎn)足的條件,一直找到鍵值21,到最后一個(gè)數(shù)據(jù)仍不能滿(mǎn)足我們的要求,此時(shí)會(huì)拿著頁(yè)8的指針P去讀取頁(yè)9的數(shù)據(jù),頁(yè)9不在內(nèi)存中同樣需要磁盤(pán)加載讀進(jìn)內(nèi)存,然后依此類(lèi)推,直到匹配到鍵值34時(shí)不滿(mǎn)足條件則終止,這就是通過(guò)聚集索引查找數(shù)據(jù)的一種方法。
非聚集索引非聚集索引或非聚簇索引(Secondary Index)就是以主鍵以外的列作為鍵值構(gòu)建的B+樹(shù)索引,索引中索引的邏輯順序與磁盤(pán)上行的物理存儲(chǔ)順序不同,一個(gè)表中可以擁有多個(gè)非聚集索引。在InnoDB中處了主鍵索引外其他索引都可以稱(chēng)為輔助索引或二級(jí)索引。
MySQL中的MyISAM使用的就是非聚集索引。表數(shù)據(jù)存儲(chǔ)順序與索引數(shù)據(jù)無(wú)關(guān),葉節(jié)點(diǎn)包含索引字段值及指向數(shù)據(jù)頁(yè)數(shù)據(jù)行的邏輯指針(其行數(shù)量與數(shù)據(jù)表數(shù)據(jù)量相同),所以想要查找數(shù)據(jù)還需要根據(jù)主鍵再去聚集索引中查找,根據(jù)聚集索引查找數(shù)據(jù)的過(guò)程就稱(chēng)為回表。
比如定義一張數(shù)據(jù)表test,他是由test.frm、tsst.myd和test.myi組成的:
.frm:記錄了表定義語(yǔ)句. myd:記錄了真實(shí)表數(shù)據(jù). myi:記錄了索引數(shù)據(jù)再檢索數(shù)據(jù)時(shí),先到索引樹(shù)test.myi中進(jìn)行查找,取到數(shù)據(jù)所在test.myd的行位置,拿到數(shù)據(jù)。所以MyISAM引擎的索引文件和數(shù)據(jù)文件是獨(dú)立分開(kāi)的,找到索引不等于找到數(shù)據(jù),即非聚集索引。
一個(gè)表可以有不止一個(gè)非聚集索引,實(shí)際上每個(gè)表最多可以建立249個(gè)非聚集索引,但是每次給字段建一個(gè)新索引,字段中的數(shù)據(jù)就會(huì)被復(fù)制出來(lái)一份用于生成索引,因此給表添加索引會(huì)增加表的體積,占據(jù)大量磁盤(pán)空間和內(nèi)存。所以若磁盤(pán)空間和內(nèi)存有限,應(yīng)限制非聚集索引數(shù)量。
此外每當(dāng)你改變了一個(gè)建立非聚集索引的表中數(shù)據(jù)時(shí),必須同時(shí)更新索引,所以非聚集索引會(huì)降低插入和更新速度。
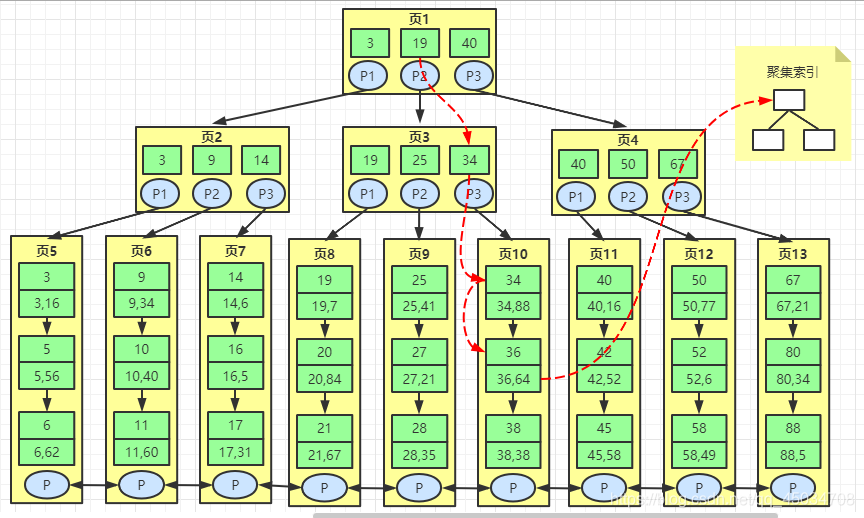
比如查找數(shù)據(jù)36,是用兩個(gè)數(shù)字表示,前面那個(gè)數(shù)字36代表的是索引的鍵值,后面那個(gè)64代表的是數(shù)據(jù)的主鍵。所以說(shuō)我們找到36后,并沒(méi)有拿到數(shù)據(jù),還要根據(jù)它對(duì)應(yīng)的主鍵去到聚集索引表中去查找數(shù)據(jù)。
聯(lián)合索引和覆蓋索引聯(lián)合索引,顧名思義就是指對(duì)表上的多個(gè)列聯(lián)合起來(lái)進(jìn)行索引。在創(chuàng)建聯(lián)合索引的時(shí)候會(huì)根據(jù)業(yè)務(wù)需求,把使用最頻繁的列放在最左邊,因?yàn)镸ySQL的索引查詢(xún)會(huì)遵循最左前綴匹配的原則。
最左前綴匹配原則即最左優(yōu)先在檢索數(shù)據(jù)的時(shí)候,從聯(lián)合索引的最左邊開(kāi)始匹配,所以當(dāng)我們創(chuàng)建一個(gè)聯(lián)合索引的時(shí)候,如(a,b,c)相當(dāng)于創(chuàng)建了(a)、(a、b)、(a、b、c)三個(gè)索引,這就是最左匹配原則。
覆蓋索引(Covering index)只是特定于具體select語(yǔ)錄而言的聯(lián)合索引。也就是說(shuō)一個(gè)聯(lián)合索引對(duì)于某個(gè)select語(yǔ)句,通過(guò)索引可以直接獲取查詢(xún)結(jié)果,而不再需要回表查詢(xún)啦,就稱(chēng)該聯(lián)合索引覆蓋了這條select語(yǔ)句。可以完美的解決非聚集索引回表查詢(xún)的問(wèn)題,但前提是注意查詢(xún)時(shí)索引的最左匹配原則。
B+樹(shù)索引VS哈希索引原理:
B+樹(shù)索引可能需要多次運(yùn)用二分查找來(lái)找到對(duì)應(yīng)的數(shù)據(jù)塊。 Hash索引時(shí)通過(guò)Hash函數(shù),計(jì)算出Hash值,在表中找出對(duì)應(yīng)的數(shù)據(jù)。哈希索引適合大量不同數(shù)據(jù)等值精確查詢(xún),但不支持模糊查詢(xún)、范圍查詢(xún),無(wú)法用索引來(lái)進(jìn)行排序,也不支持聯(lián)合索引的最左匹配原則,而且有大量重復(fù)鍵值的情況下,還會(huì)存在哈希碰撞問(wèn)題。
普通索引和唯一索引普通索引的字段可以寫(xiě)入重復(fù)的值,而唯一索引的字段不能寫(xiě)入重復(fù)的值。先介紹Insert Buffer和Change Buffer:
Insert Buffer 對(duì)于非聚集索引的插入,先判斷插入的非聚集索引是在在緩存池中。若在則直接插入,若不在,則先放入Insert Buffer,之后在一一定頻率和情況鏡像Insert Buffer和輔助索引頁(yè)子節(jié)點(diǎn)的合并操作。將多次插入合并為一次操作,減少磁盤(pán)離散讀取。要求索引是輔助索引且不唯一。 Change Buffer 是Insert Buffer的升級(jí)版,除了插入還支持刪改。通過(guò)innodb_change_buffer設(shè)置使用場(chǎng)景,默認(rèn)為all(還有none、inserts、changes等值),通過(guò)innodb_change_buffer_max_size設(shè)置最大使用內(nèi)存占比(默認(rèn)25%,最大值50%),但在RR隔離級(jí)別下會(huì)出現(xiàn)死鎖。同樣要求索引是輔助索引且不唯一。唯一索引使用的是Insert Buffer,因?yàn)榕袛嗍欠襁`反唯一性約束,如果都已經(jīng)讀入內(nèi)存了,那直接更新內(nèi)存會(huì)更快,就沒(méi)必要使用Change Buffer。
普通索引查找到滿(mǎn)足條件的第一個(gè)記錄后,繼續(xù)查找下一個(gè)記錄直到不滿(mǎn)足條件,對(duì)唯一索引來(lái)說(shuō),查到第一個(gè)記錄就返回結(jié)果結(jié)束了。但是InnoDB按頁(yè)讀取到內(nèi)存,后面滿(mǎn)足條件的可能都在之前的數(shù)據(jù)頁(yè)里,所以普通索引多的幾次內(nèi)存掃描消耗可以忽略不計(jì)。
小結(jié):
數(shù)據(jù)修改時(shí),普通索引可用Change Buffer,而唯一索引不行。 數(shù)據(jù)修改時(shí),唯一索引在RR隔離級(jí)別下更容易出現(xiàn)死鎖。 查詢(xún)數(shù)據(jù)時(shí),普通索引查到一條記錄還需繼續(xù)判斷下一個(gè)記錄,而唯一索引查到后直接返回。 當(dāng)業(yè)務(wù)要求某字段唯一時(shí),若代碼能保證寫(xiě)入唯一值,則用普通索引,否則用唯一索引。InnoDB VS MyISAM MyISAM InnoDB 數(shù)據(jù)存儲(chǔ) .frm存儲(chǔ)表定義、.myd數(shù)據(jù)文件、.myi索引文件 不開(kāi)啟獨(dú)立表空間則.frm文件,否則idb文件 索引實(shí)現(xiàn) 非聚集索引隨機(jī)存儲(chǔ),只緩存索引 聚集索引順序存儲(chǔ),緩存索引和數(shù)據(jù) 存儲(chǔ)空間 可被壓縮,存儲(chǔ)空間較小,支持靜態(tài)表、動(dòng)態(tài)表、壓縮表三種格式 需更多內(nèi)存和存儲(chǔ) 備份恢復(fù) 文件形式存儲(chǔ)可跨平臺(tái),可單獨(dú)針對(duì)某個(gè)表操作 拷貝數(shù)據(jù)文件、備份binlog,體量可能非常大 事務(wù) 不支持(也不支持外鍵,更強(qiáng)調(diào)性能) 支持(包括外鍵、安全、回滾等高級(jí)功能) auto_increment 自增長(zhǎng)列必須是索引,聯(lián)合索引中可不是第一列 自增長(zhǎng)列必須是索引,聯(lián)合索引中也必須是第一列 鎖 支持表級(jí)鎖 支持行級(jí)鎖 全文索引 支持FULLTEXT類(lèi)型全文索引 不支持FULLTEXT,但可使用Sphinx插件 表主鍵 允許沒(méi)有任何索引和主鍵的表存在 會(huì)自動(dòng)生成隱藏主鍵 總行數(shù) 保存有表的總行數(shù) 沒(méi)有保存表的總行數(shù),會(huì)使用輔助索引去遍歷 CRUD 相對(duì)適合大量查詢(xún) 相對(duì)適合增改刪對(duì)比之下,基本上可以考慮使用InnoDB來(lái)替代MyISAM了,InnoDB也是目前MySQL的默認(rèn)引擎,但是具體問(wèn)題具體分析,也可根據(jù)實(shí)際情況對(duì)比兩者優(yōu)劣,選擇更合適的。
再擴(kuò)展一下為什么MyISAM查詢(xún)比InnoDB快?
InnoDB要緩存數(shù)據(jù)和索引;MyISAM只緩存索引,換進(jìn)換出的減少。 InnoDB尋址要映射到塊再到行;MyISAM直接記錄文件的OFFSET,定位更快。 InnoDB還要維護(hù)MVCC一致,或許你的場(chǎng)景沒(méi)有,但也需要檢查和維護(hù)。MVCC(Multi-Version Concurrency Control)多版本并發(fā)控制
InnoDB為每一行記錄添加了兩個(gè)額外的隱藏值(創(chuàng)建版本號(hào)、刪除版本號(hào))來(lái)實(shí)現(xiàn)MVCC,一個(gè)記錄行數(shù)據(jù)創(chuàng)建時(shí)間,一個(gè)記錄行數(shù)據(jù)過(guò)期/刪除時(shí)間。但是InnoDB并不存儲(chǔ)這些事件發(fā)生的實(shí)際時(shí)間,相反它只存儲(chǔ)這些事件發(fā)生時(shí)的系統(tǒng)版本號(hào)。隨著事務(wù)的不斷創(chuàng)建而不斷增長(zhǎng),每個(gè)事務(wù)在開(kāi)始時(shí)都會(huì)記錄它自己的系統(tǒng)版本號(hào),每個(gè)查詢(xún)必須去檢查每行數(shù)據(jù)的版本號(hào)與事務(wù)的版本號(hào)是否相同。也就是說(shuō)每行數(shù)據(jù)的創(chuàng)建版本號(hào)不大于事務(wù)版本號(hào),以確保事務(wù)創(chuàng)建前行數(shù)據(jù)是存在的;行數(shù)據(jù)的刪除版本號(hào)大于事務(wù)版本號(hào)或未定義,以確保事務(wù)開(kāi)始前行數(shù)據(jù)沒(méi)有被刪除。
用explain分析索引使用explain可以看SQL語(yǔ)句的執(zhí)行效果,可以幫助選擇更好的索引和優(yōu)化查詢(xún)語(yǔ)句,語(yǔ)法:explain select... from ... [where...]。
用前面概述那節(jié)的test表做測(cè)試:
mysql> explain select * from test where a=88888;+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------+| 1 | SIMPLE | test | NULL | ref | idx_a | idx_a | 5 | const | 1 | 100.00 | NULL |+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------+1 row in set, 1 warning (0.03 sec)mysql> explain select b,c from test where b=88888;+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+| 1 | SIMPLE | test | NULL | ref | idx_b_c | idx_b_c | 5 | const | 1 | 100.00 | Using index |+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)mysql> explain select * from test where a=(select a from test where a=88888);+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------------+| 1 | PRIMARY | test | NULL | ref | idx_a | idx_a | 5 | const | 1 | 100.00 | Using where || 2 | SUBQUERY | test | NULL | ref | idx_a | idx_a | 5 | const | 1 | 100.00 | Using index |+----+-------------+-------+------------+------+---------------+-------+---------+-------+------+----------+-------------+2 rows in set, 1 warning (0.00 sec)
重點(diǎn)看這三列即可:select_type、type、extra。
select_type值 說(shuō)明 SIMPLE 簡(jiǎn)單查詢(xún)(不使用關(guān)聯(lián)查詢(xún)或子查詢(xún)) PRIMARY 包含關(guān)聯(lián)查詢(xún)或子查詢(xún) UNION 聯(lián)合查詢(xún)中第二個(gè)及后面的查詢(xún) DEPENDENT UNION 依賴(lài)外部的關(guān)聯(lián)查詢(xún)中第二個(gè)及以后的查詢(xún) UNION RESULT 聯(lián)合查詢(xún)結(jié)果 SUBQUERY 子查詢(xún)中的第一個(gè)查詢(xún) DEPENDENT SUBQUERY 依賴(lài)外部查詢(xún)的子查詢(xún)中的第一個(gè)查詢(xún) DERIVED 用到派生表的查詢(xún) MATERIALIZED 被物化的子查詢(xún) UNCACHEABLE SUBQUERY 子查詢(xún)結(jié)果不能被緩存,必須重新評(píng)估外層查詢(xún)的每一行type(顯示這一行的數(shù)據(jù)是關(guān)于哪張表的)
type的值 說(shuō)明 system 查詢(xún)對(duì)象只有一會(huì)數(shù)據(jù) ,最好的情況 const 基于注解或唯一索引查詢(xún),最多返回一條結(jié)果 eq_ref 表連接時(shí)基于主鍵或非NULL的唯一索引完成掃描 ref 基于普通索引的等值查詢(xún)或表間等值連接 fulltest 全文檢索 ref_or_null 表連接類(lèi)型是ref,但掃描的索引中可能包含NULL值 index_merge 利用多個(gè)索引 unique_subquery 子查詢(xún)使用唯一索引 index_subquery 子查詢(xún)使用普通索引 range 利用索引進(jìn)行范圍查詢(xún) index 全索引掃描extra(解決查詢(xún)的詳細(xì)信息)
extra的值 說(shuō)明 Using filesort 用的外部排序而不是索引排序 Using temporary 需創(chuàng)建一個(gè)臨時(shí)表來(lái)存儲(chǔ)結(jié)構(gòu),通常發(fā)生在對(duì)沒(méi)有索引的列進(jìn)行g(shù)roup by時(shí) Using index 使用覆蓋索引 Using where 使用where來(lái)處理結(jié)果 Impossible where 對(duì)where子句判斷結(jié)果總是false而不能選擇任何數(shù)據(jù) Using join buffer 關(guān)聯(lián)查詢(xún)中,被驅(qū)動(dòng)表的關(guān)聯(lián)字段沒(méi)有索引 Using index condition 先條件過(guò)濾索引再查數(shù)據(jù) Select tables optimized away 使用聚合函數(shù)來(lái)訪問(wèn)存在索引的某個(gè)字段 總結(jié)本篇文章就到這里了,希望能給你帶來(lái)幫助,也希望您能夠多多關(guān)注好吧啦網(wǎng)的更多內(nèi)容!
相關(guān)文章:
1. DB2 變更管理工具與Rational DA集成(1)2. Window7安裝MariaDB數(shù)據(jù)庫(kù)及系統(tǒng)初始化操作分析3. Mysql InnoDB的鎖定機(jī)制實(shí)例詳解4. ORA-06512數(shù)字或值錯(cuò)誤字符串緩沖區(qū)太小異常詳解5. oracle觸發(fā)器介紹6. 用shell抽取,更新db2的數(shù)據(jù)7. 整理Oracle數(shù)據(jù)庫(kù)碎片8. MySQL中 concat函數(shù)的使用9. Access數(shù)據(jù)庫(kù)安全的幾個(gè)問(wèn)題10. Delphi中的Access技巧集
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備