python自動(dòng)下載圖片的方法示例
近日閑來(lái)無(wú)事,總有一種無(wú)形的力量縈繞在朕身邊,讓朕精神渙散,昏昏欲睡。

可是,像朕這么有職業(yè)操守的社畜怎么能在上班期間睡瞌睡呢,我不禁陷入了沉思。。。。

突然旁邊的IOS同事問(wèn):‘嘿,兄弟,我發(fā)現(xiàn)一個(gè)網(wǎng)站的圖片很有意思啊,能不能幫我保存下來(lái)提升我的開(kāi)發(fā)靈感?’作為一個(gè)堅(jiān)強(qiáng)的社畜怎么能說(shuō)自己不行呢,當(dāng)時(shí)朕就不假思索的答應(yīng):‘oh, It’s simple. Wait for me a few minute.’

點(diǎn)開(kāi)同事給的圖片網(wǎng)站,
網(wǎng)站大概長(zhǎng)這樣:
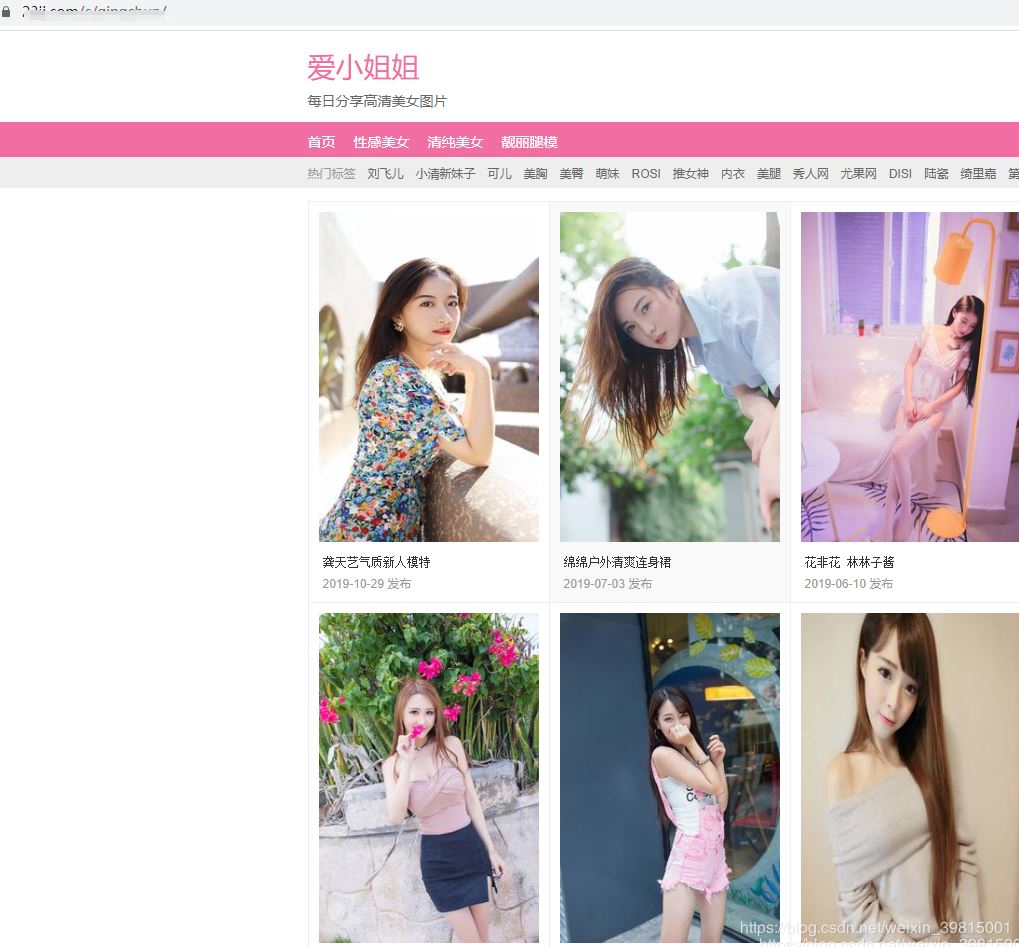
在朕翻看了幾十頁(yè)之后,朕突然覺(jué)得有點(diǎn)上頭。心中一想’不對(duì)啊,朕不是來(lái)學(xué)習(xí)的嗎?可是看美女圖片這個(gè)事情怎么才可以和學(xué)習(xí)關(guān)聯(lián)起來(lái)呢‘

冥思苦想一番之后,突然腦中靈光一閃,’要不用python寫個(gè)爬蟲(chóng)吧,將此網(wǎng)站的圖片一網(wǎng)打盡‘。

說(shuō)干就干,身體力行,要問(wèn)爬蟲(chóng)哪家強(qiáng),‘人生苦短,我用python’。
首先找到我的電腦里面半年前下載的python安裝包,無(wú)情的點(diǎn)擊了安裝,環(huán)境裝好之后,略一分析網(wǎng)頁(yè)結(jié)構(gòu)。先擼一個(gè)簡(jiǎn)易版爬蟲(chóng)
#抓取愛(ài)小姐姐網(wǎng)圖片保存到本地import requestsfrom lxml import etree as etimport os#請(qǐng)求頭headers = { #用戶代理 ’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36’}#待抓取網(wǎng)頁(yè)基地址base_url = ’’#保存圖片基本路徑base_dir = ’D:/python/code/aixjj/’#保存圖片def savePic(pic_url): #如果目錄不存在,則新建 if not os.path.exists(base_dir): os.makedirs(base_dir) arr = pic_url.split(’/’) file_name = base_dir+arr[-2]+arr[-1] print(file_name) #獲取圖片內(nèi)容 response = requests.get(pic_url, headers = headers) #寫入圖片 with open(file_name,’wb’) as fp: for data in response.iter_content(128): fp.write(data)#觀察此網(wǎng)站總共只有62頁(yè),所以循環(huán)62次for k in range(1,63): #請(qǐng)求頁(yè)面地址 url = base_url+str(k) response = requests.get(url = url, headers = headers) #請(qǐng)求狀態(tài)碼 code = response.status_code if code == 200: html = et.HTML(response.text) #獲取頁(yè)面所有圖片地址 r = html.xpath(’//li/a/img/@src’) #獲取下一頁(yè)url #t = html.xpath(’//div[@class='page']/a[@class='ch']/@href’)[-1] for pic_url in r: a = ’http:’+pic_url savePic(a) print(’第%d頁(yè)圖片下載完成’ % (k))print(’The End!’)
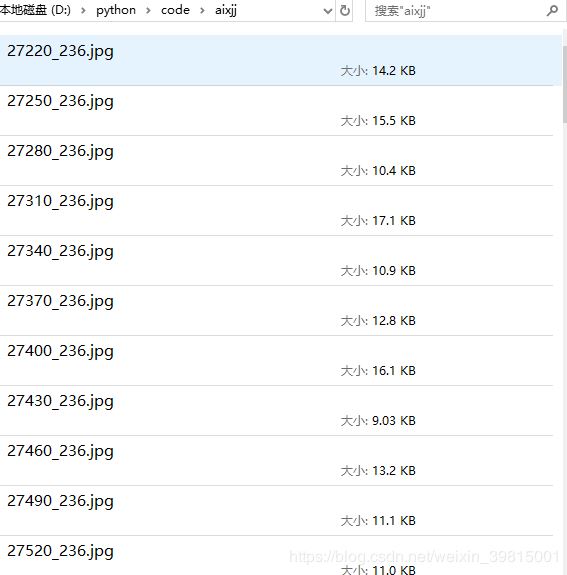
嘗試運(yùn)行爬蟲(chóng),嘿,沒(méi)想到行了:

過(guò)了一會(huì)兒,旁邊的哥們兒又來(lái):‘嘿 bro 你這個(gè)可以是可以,就是速度太慢了啊,我的靈感會(huì)被長(zhǎng)時(shí)間的等待磨滅,你給改進(jìn)改進(jìn)?’

怎么提升爬蟲(chóng)的效率呢?略一思索,公司的電腦可是偉大的四核CPU啊,要不擼個(gè)多進(jìn)程版本試試。然后就產(chǎn)生了下面這個(gè)多進(jìn)程版本
#多進(jìn)程版——抓取愛(ài)小姐姐網(wǎng)圖片保存到本地import requestsfrom lxml import etree as etimport osimport timefrom multiprocessing import Pool#請(qǐng)求頭headers = { #用戶代理 ’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36’}#待抓取網(wǎng)頁(yè)基地址base_url = ’’#保存圖片基本路徑base_dir = ’D:/python/code/aixjj1/’#保存圖片def savePic(pic_url): #如果目錄不存在,則新建 if not os.path.exists(base_dir): os.makedirs(base_dir) arr = pic_url.split(’/’) file_name = base_dir+arr[-2]+arr[-1] print(file_name) #獲取圖片內(nèi)容 response = requests.get(pic_url, headers = headers) #寫入圖片 with open(file_name,’wb’) as fp: for data in response.iter_content(128): fp.write(data)def geturl(url): #請(qǐng)求頁(yè)面地址 #url = base_url+str(k) response = requests.get(url = url, headers = headers) #請(qǐng)求狀態(tài)碼 code = response.status_code if code == 200: html = et.HTML(response.text) #獲取頁(yè)面所有圖片地址 r = html.xpath(’//li/a/img/@src’) #獲取下一頁(yè)url #t = html.xpath(’//div[@class='page']/a[@class='ch']/@href’)[-1] for pic_url in r: a = ’http:’+pic_url savePic(a)if __name__ == ’__main__’: #獲取要爬取的鏈接列表 url_list = [base_url+format(i) for i in range(1,100)] a1 = time.time() #利用進(jìn)程池方式創(chuàng)建進(jìn)程,默認(rèn)創(chuàng)建進(jìn)程數(shù)量=電腦核數(shù) #自己定義進(jìn)程數(shù)量方式 pool = Pool(4) pool = Pool() pool.map(geturl,url_list) pool.close() pool.join() b1 = time.time() print(’運(yùn)行時(shí)間:’,b1-a1)
抱著試一試的心態(tài),運(yùn)行了多進(jìn)程版本爬蟲(chóng),嘿?zèng)]想到又行了,在朕偉大的四核CPU的加持下,爬蟲(chóng)速度提升了3~4倍。又過(guò)了一會(huì)兒,那哥們兒又偏過(guò)頭來(lái):‘你這個(gè)快是快了不少,但是還不是最理想的狀態(tài),能不能一眨眼就能爬取百八十個(gè)圖片,畢竟我的靈感來(lái)的快去的也快’
我:‘…’悄悄打開(kāi)Google,搜索如何提升爬蟲(chóng)效率,給出結(jié)論:
多進(jìn)程:密集CPU任務(wù),需要充分使用多核CPU資源(服務(wù)器,大量的并行計(jì)算)的時(shí)候,用多進(jìn)程。多線程:密集I/O任務(wù)(網(wǎng)絡(luò)I/O,磁盤I/O,數(shù)據(jù)庫(kù)I/O)使用多線程合適。
呵,我這可不就是I/O密集任務(wù)嗎,趕緊寫一個(gè)多線程版爬蟲(chóng)先。于是,又誕生了第三款:
import threading # 導(dǎo)入threading模塊from queue import Queue #導(dǎo)入queue模塊import time #導(dǎo)入time模塊import requestsimport osfrom lxml import etree as et#請(qǐng)求頭headers = { #用戶代理 ’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36’}#待抓取網(wǎng)頁(yè)基地址base_url = ’’#保存圖片基本路徑base_dir = ’D:/python/code/aixjj/’#保存圖片def savePic(pic_url): #如果目錄不存在,則新建 if not os.path.exists(base_dir): os.makedirs(base_dir) arr = pic_url.split(’/’) file_name = base_dir+arr[-2]+arr[-1] print(file_name) #獲取圖片內(nèi)容 response = requests.get(pic_url, headers = headers) #寫入圖片 with open(file_name,’wb’) as fp: for data in response.iter_content(128): fp.write(data)# 爬取文章詳情頁(yè)def get_detail_html(detail_url_list, id): while True: url = detail_url_list.get() #Queue隊(duì)列的get方法用于從隊(duì)列中提取元素 response = requests.get(url = url, headers = headers) #請(qǐng)求狀態(tài)碼 code = response.status_code if code == 200: html = et.HTML(response.text) #獲取頁(yè)面所有圖片地址 r = html.xpath(’//li/a/img/@src’) #獲取下一頁(yè)url #t = html.xpath(’//div[@class='page']/a[@class='ch']/@href’)[-1] for pic_url in r:a = ’http:’+pic_urlsavePic(a)# 爬取文章列表頁(yè)def get_detail_url(queue): for i in range(1,100): #time.sleep(1) # 延時(shí)1s,模擬比爬取文章詳情要快 #Queue隊(duì)列的put方法用于向Queue隊(duì)列中放置元素,由于Queue是先進(jìn)先出隊(duì)列,所以先被Put的URL也就會(huì)被先get出來(lái)。 page_url = base_url+format(i) queue.put(page_url) print('put page url {id} end'.format(id = page_url))#打印出得到了哪些文章的url#主函數(shù)if __name__ == '__main__': detail_url_queue = Queue(maxsize=1000) #用Queue構(gòu)造一個(gè)大小為1000的線程安全的先進(jìn)先出隊(duì)列 #A線程負(fù)責(zé)抓取列表url thread = threading.Thread(target=get_detail_url, args=(detail_url_queue,)) html_thread= [] #另外創(chuàng)建三個(gè)線程負(fù)責(zé)抓取圖片 for i in range(20): thread2 = threading.Thread(target=get_detail_html, args=(detail_url_queue,i)) html_thread.append(thread2)#B C D 線程抓取文章詳情 start_time = time.time() # 啟動(dòng)四個(gè)線程 thread.start() for i in range(20): html_thread[i].start() # 等待所有線程結(jié)束,thread.join()函數(shù)代表子線程完成之前,其父進(jìn)程一直處于阻塞狀態(tài)。 thread.join() for i in range(20): html_thread[i].join() print('last time: {} s'.format(time.time()-start_time))#等ABCD四個(gè)線程都結(jié)束后,在主進(jìn)程中計(jì)算總爬取時(shí)間。
粗略測(cè)試一下,得出結(jié)論: ‘Oh my god,這也太快了吧’。將多線程版本爬蟲(chóng)扔到同事QQ頭像的臉上,并附文:‘拿去,速滾’
到此這篇關(guān)于python自動(dòng)下載圖片的方法示例的文章就介紹到這了,更多相關(guān)python 自動(dòng)下載圖片內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. msxml3.dll 錯(cuò)誤 800c0019 系統(tǒng)錯(cuò)誤:-2146697191解決方法2. ASP中if語(yǔ)句、select 、while循環(huán)的使用方法3. html小技巧之td,div標(biāo)簽里內(nèi)容不換行4. ASP中解決“對(duì)象關(guān)閉時(shí),不允許操作。”的詭異問(wèn)題……5. 匹配模式 - XSL教程 - 46. XML入門的常見(jiàn)問(wèn)題(四)7. WML語(yǔ)言的基本情況8. xml中的空格之完全解說(shuō)9. CSS3中Transition屬性詳解以及示例分享10. 解決ASP中http狀態(tài)跳轉(zhuǎn)返回錯(cuò)誤頁(yè)的問(wèn)題
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備