Python使用Chrome插件實現(xiàn)爬蟲過程圖解
做電商時,消費者對商品的評論是很重要的,但是不會寫代碼怎么辦?這里有個Chrome插件可以做到簡單的數(shù)據(jù)爬取,一句代碼都不用寫。下面給大家展示部分抓取后的數(shù)據(jù):

可以看到,抓取的地址,評論人,評論內(nèi)容,時間,產(chǎn)品顏色都已經(jīng)抓取下來了。那么,爬取這些數(shù)據(jù)需要哪些工具呢?就兩個:
1. Chrome瀏覽器;
2. 插件:Web Scraper
插件下載地址:https://chromecj.com/productivity/2018-05/942.html
最后,如果你想自己動手抓取一下,這里是這次抓取的詳細過程:
1. 首先,復(fù)制如下的代碼,對,你不需要寫代碼,但是為了便于上手,復(fù)制代碼還是需要的,后續(xù)可以自己定制和選擇,不需要寫代碼。
{ '_id': 'jdreview', 'startUrl': [ 'https://item.jd.com/100000680365.html#comment' ], 'selectors': [ { 'id': 'user', 'type': 'SelectorText', 'selector': 'div.user-info', 'parentSelectors': ['main' ], 'multiple': false, 'regex': '', 'delay': 0 }, { 'id': 'comments', 'type': 'SelectorText', 'selector': 'div.comment-column > p.comment-con', 'parentSelectors': ['main' ], 'multiple': false, 'regex': '', 'delay': 0 }, { 'id': 'time', 'type': 'SelectorText', 'selector': 'div.comment-message:nth-of-type(5) span:nth-of-type(4), div.order-info span:nth-of-type(4)', 'parentSelectors': ['main' ], 'multiple': false, 'regex': '', 'delay': '0' }, { 'id': 'color', 'type': 'SelectorText', 'selector': 'div.order-info span:nth-of-type(1)', 'parentSelectors': ['main' ], 'multiple': false, 'regex': '', 'delay': 0 }, { 'id': 'main', 'type': 'SelectorElementClick', 'selector': 'div.comment-item', 'parentSelectors': ['_root' ], 'multiple': true, 'delay': '10000', 'clickElementSelector': 'div.com-table-footer a.ui-pager-next', 'clickType': 'clickMore', 'discardInitialElements': false, 'clickElementUniquenessType': 'uniqueHTMLText' } ]}
2. 然后打開chrome瀏覽器,在任意頁面同時按下Ctrl+Shift+i,在彈出的窗口中找到Web Scraper,如下:
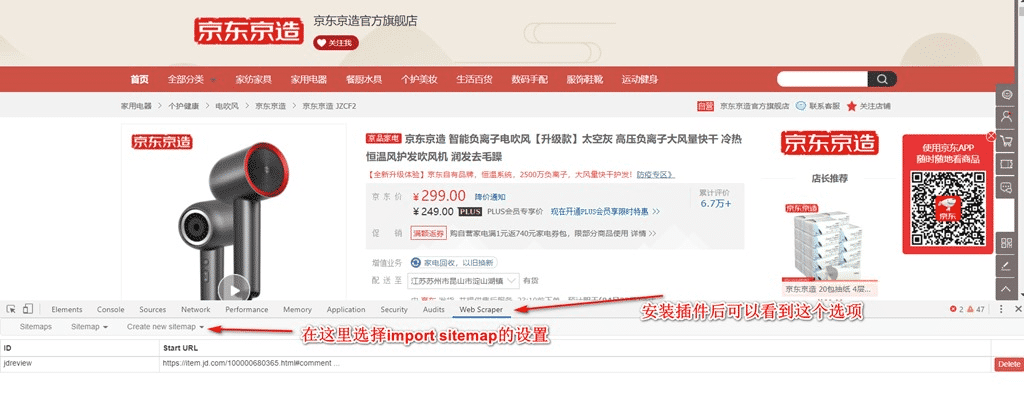
3. 如下
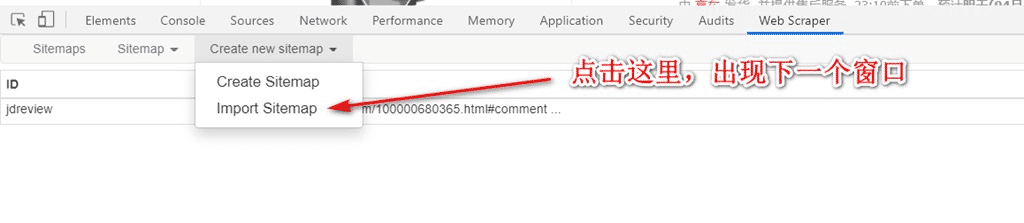
4. 如圖,粘貼上述的代碼:

5. 如圖,如果需要定制網(wǎng)址,注意替代一下,網(wǎng)址后面的#comment是直達評論的鏈接,不能去掉:

6. 如圖:

7. 如圖:
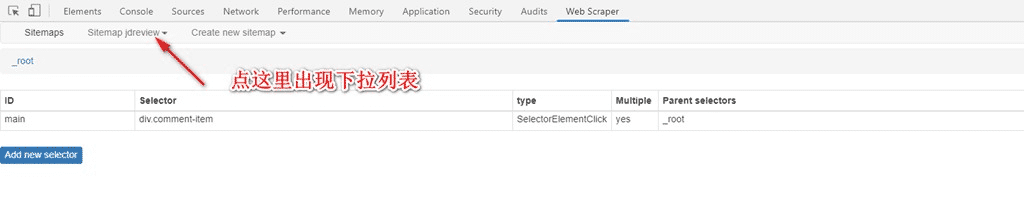
8. 如圖,點擊Scrape后,會自動運行打開需要抓取得頁面,不要關(guān)閉窗口,靜靜等待完成,完成后右下方會提示完成,一般1000條以內(nèi)的評論不會有問題:
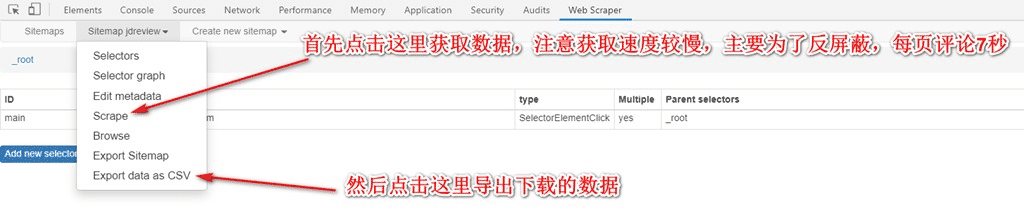
9. 最后,點擊下載到電腦,數(shù)據(jù)保存好。
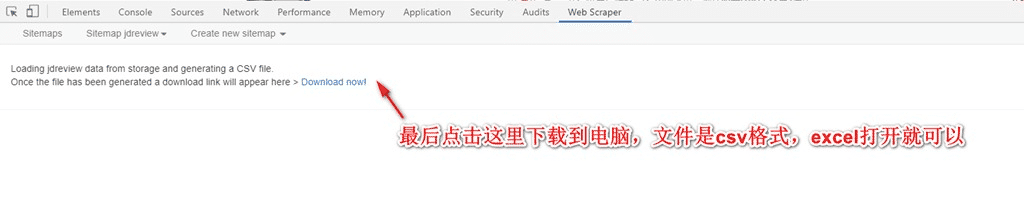
使用這個工具的好處是:
1. 不需要編程;
2. 京東的評論基本可以通用此腳本,修改對應(yīng)的url即可;
3. 如果需要爬取的評論不到1000條,這個工具會非常稱手,所有的數(shù)據(jù)完全自動下載;
使用的注意點:
1. 抓取過一次的數(shù)據(jù)會有記錄,立刻再次抓取將不會保存,建議關(guān)閉瀏覽器重新打開后再試;
2. 抓取數(shù)量:1000條以內(nèi)沒有問題,可能是京東按照IP直接阻止了更多的爬取;
如果你的英語水平不錯,可以嘗試閱讀官方文檔,進一步學(xué)習(xí)和定制自己的爬蟲。
官方教程:https://www.webscraper.io/documentation
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持好吧啦網(wǎng)。
相關(guān)文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備