Python lxml庫的簡單介紹及基本使用講解
lxml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的數(shù)據(jù);lxml和正則一樣,也是用C語言實(shí)現(xiàn)的,是一款高性能的python HTML、XML解析器,也可以利用XPath語法,來定位特定的元素及節(jié)點(diǎn)信息
HTML是超文本標(biāo)記語言,主要用于顯示數(shù)據(jù),他的焦點(diǎn)是數(shù)據(jù)的外觀XML是可擴(kuò)展標(biāo)記語言,主要用于傳輸和存儲(chǔ)數(shù)據(jù),他的焦點(diǎn)是數(shù)據(jù)的內(nèi)容
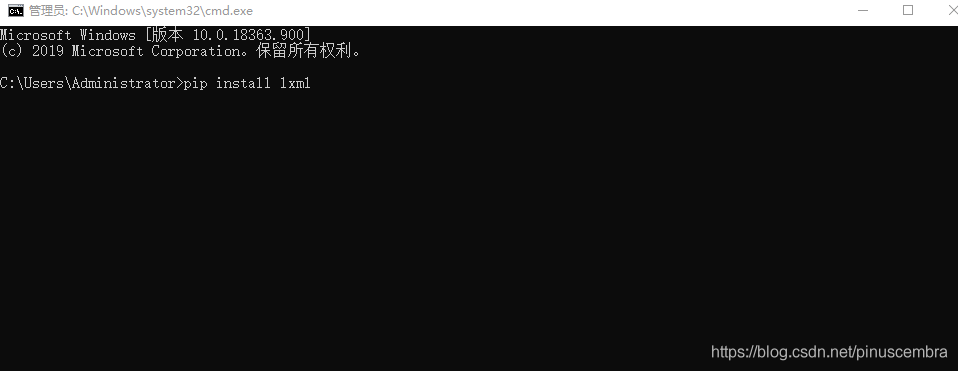
2.安裝lxml方法方法1:在cmd運(yùn)行窗口中輸入:pip install lxml
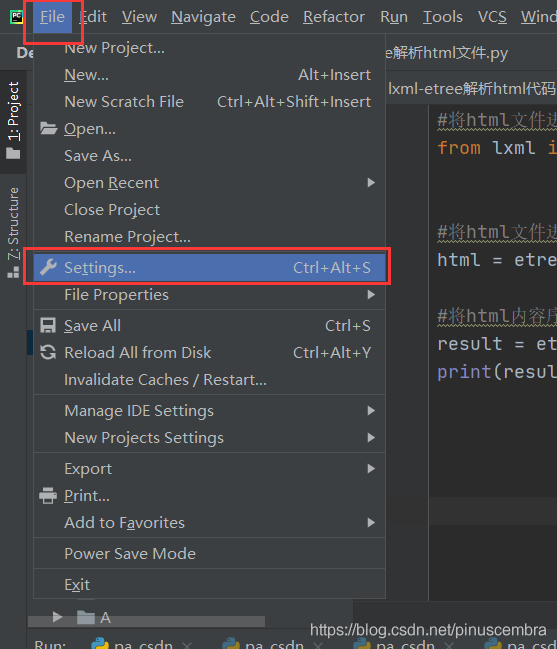
方法2:在Pycharm中下載File?Setting?Project?Project Interpreter?點(diǎn)擊右上角的“+”—第1步
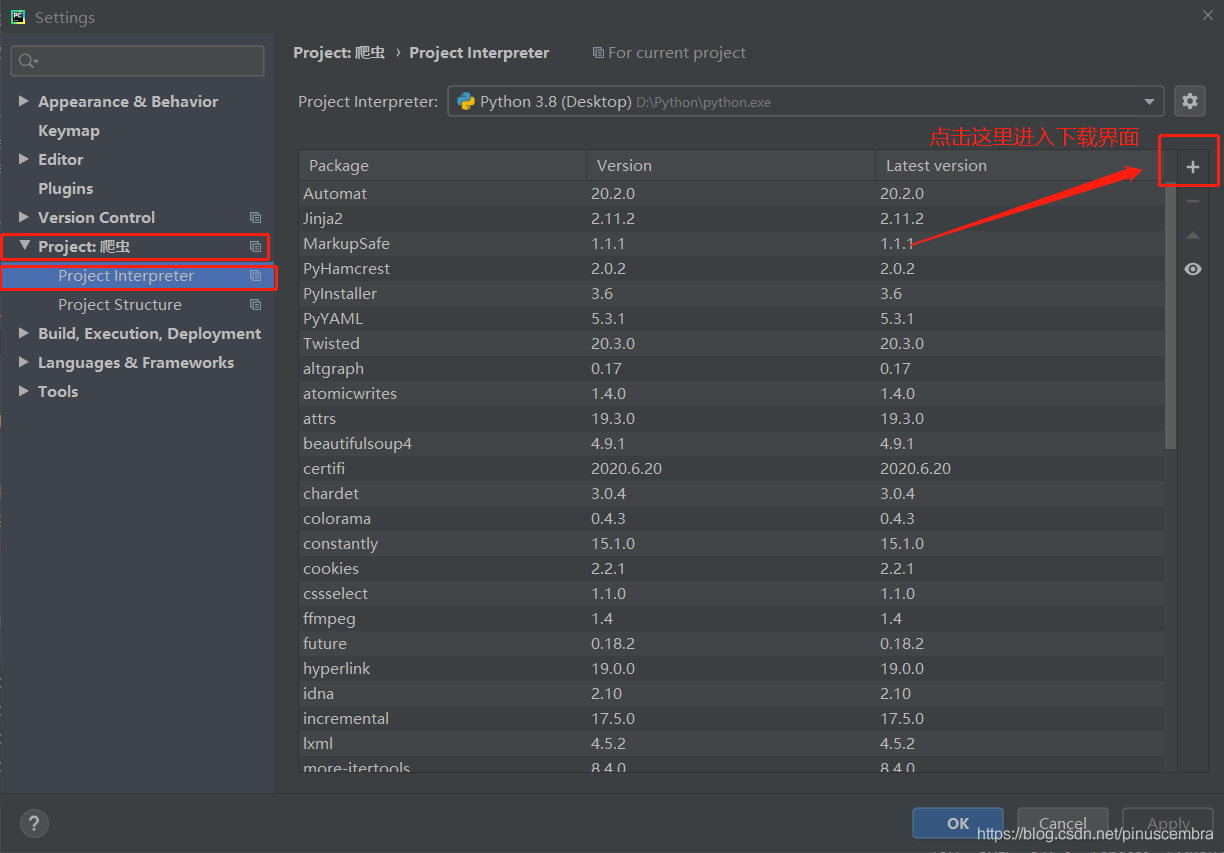
第2步
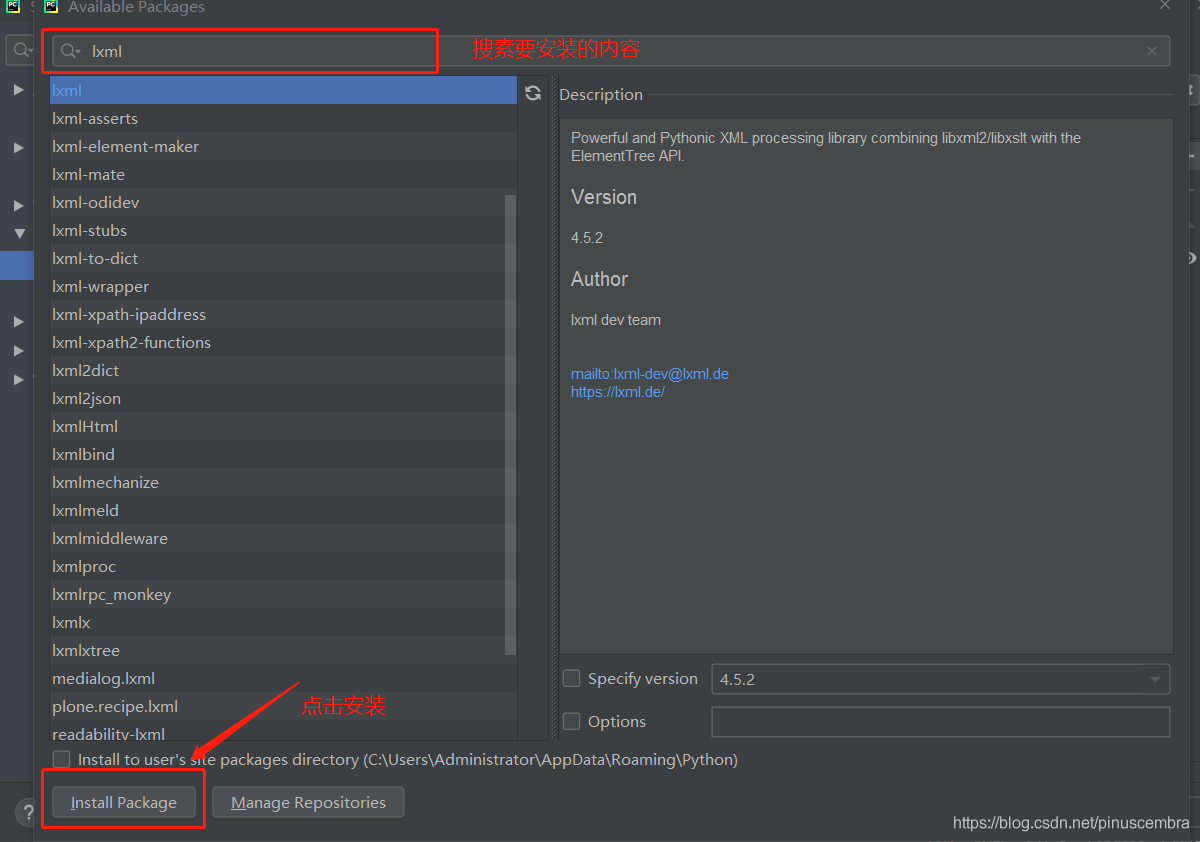
第3步
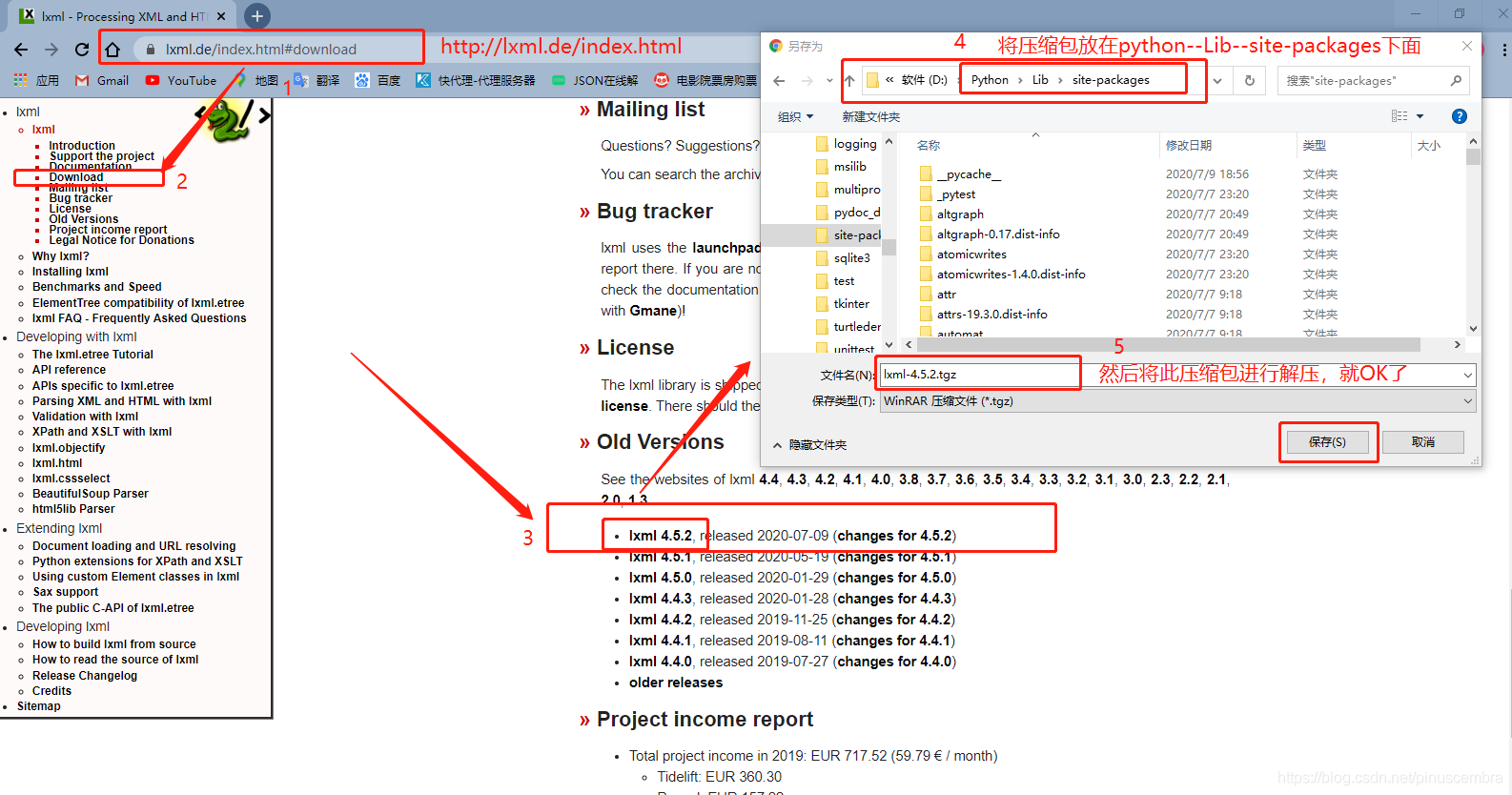
方法3:進(jìn)入這個(gè)網(wǎng)站進(jìn)行下載:https://lxml.de/index.html
我們可以利用他解析HTML代碼,并且在解析HTML代碼的時(shí)候,如果HTML代碼不規(guī)范或者不完整,lxml解析器會(huì)自動(dòng)修復(fù)或補(bǔ)全代碼,從而提高效率
實(shí)例1:解析HTML代碼塊
#提取html中的數(shù)據(jù)from lxml import etreetext = ’’’<html> <div class='clearfix'> <div class='nav_com'> <ul> <li class='active'><a href='http://m.baoyu77737.com/' rel='external nofollow' >推薦</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/python' rel='external nofollow' >Python</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/java' rel='external nofollow' >Java</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/web' rel='external nofollow' >前端</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/arch' rel='external nofollow' >架構(gòu)</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/db' rel='external nofollow' >數(shù)據(jù)庫</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/5g' rel='external nofollow' >5G</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/game' rel='external nofollow' >游戲開發(fā)</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/mobile' rel='external nofollow' >移動(dòng)開發(fā)</a></li> <li class=''><a href='http://m.baoyu77737.com/nav/ops' rel='external nofollow' >運(yùn)維</a></li> </ul> </div> </div></html>></html>>’’’#將字符串解析為html文檔html = etree.HTML(text)#print(html)#將字符串序列化為htmlresult = etree.tostring(html).decode(’utf-8’)print(result)
實(shí)例2:讀取并解析html文件
#將html文件進(jìn)行解析from lxml import etree#將html文件進(jìn)行讀取html = etree.parse(’data.html’)#將html內(nèi)容序列化result = etree.tostring(html).decode(’utf-8’)print(result)
到此這篇關(guān)于Python lxml庫的簡單介紹及基本使用講解的文章就介紹到這了,更多相關(guān)Python lxml庫使用內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. python實(shí)現(xiàn)讀取類別頻數(shù)數(shù)據(jù)畫水平條形圖案例2. python中PyQuery庫用法分享3. python操作數(shù)據(jù)庫獲取結(jié)果之fetchone和fetchall的區(qū)別說明4. php使用正則驗(yàn)證密碼字段的復(fù)雜強(qiáng)度原理詳細(xì)講解 原創(chuàng)5. Ajax實(shí)現(xiàn)頁面無刷新留言效果6. python 爬取嗶哩嗶哩up主信息和投稿視頻7. 關(guān)于HTML5的img標(biāo)簽8. PHP獲取時(shí)間戳等相關(guān)函數(shù)匯總9. CSS3實(shí)現(xiàn)動(dòng)態(tài)翻牌效果 仿百度貼吧3D翻牌一次動(dòng)畫特效10. JSP+Servlet實(shí)現(xiàn)文件上傳到服務(wù)器功能
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備