文章詳情頁
網頁爬蟲 - 關于python beautifullsoup解析網頁內容丟失的問題?
瀏覽:132日期:2022-09-23 08:23:07
問題描述
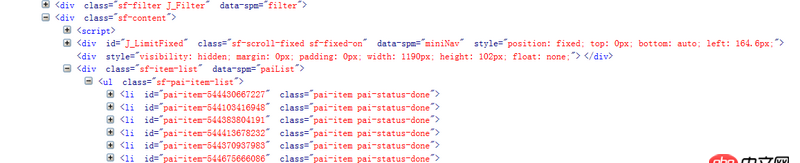
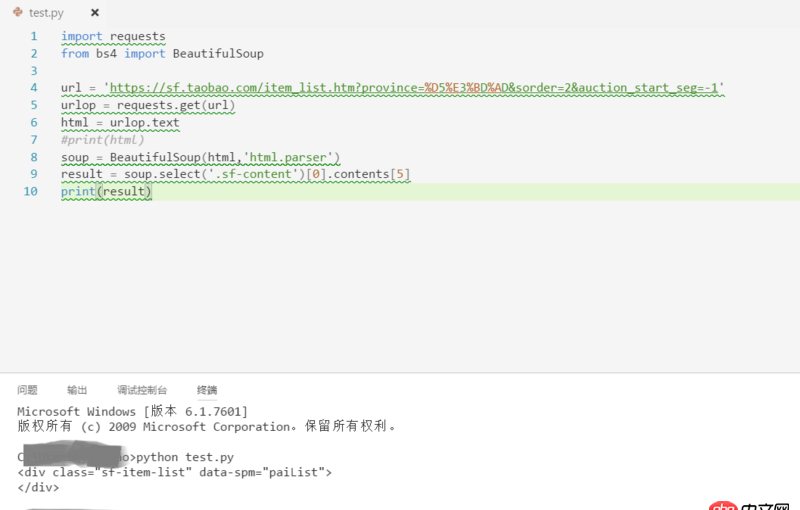
待解析頁面的部分代碼如第一幅圖所示,我自己寫的代碼及運行結果如第二幅圖所示。看到已經有答主提問解析頁面丟失是因為用的是lxml的解析方式,我想說我一直用的是html.parser的方式。希望各位大神不吝賜教~
問題解答
回答1:你們從來都不考慮javascript動態加載的嗎?
回答2:題主,如果你用Chrome F12看的話,里面是會有動態加載的內容的,而這些內容你直接請求頁面的url是拿不到的。建議你點右鍵查看網頁源代碼,對照著F12里面的內容來看,源代碼里沒有的內容,就去查看Network里的其他請求,看有沒有你需要的數據。
相關文章:
1. Docker for Mac 創建的dnsmasq容器連不上/不工作的問題2. css3 - 圖片等比例縮放3. html - css3中多列高度 統一4. javascript - 使用angular 的ui-sref 中出現了中文參數,點擊跳轉后瀏覽器的地址欄里出現轉義后的%AE....%a%45. css3 - 如何將網頁CSS背景圖高斯模糊且全屏顯示6. javascript - 一個賦值運算的問題7. css3 - animation屬性,safari瀏覽器不支持相關效果8. javascript - 求賜教:網易郵箱Web端模擬登錄看信的加密參數_ntes_nnid、_ntes_nuid9. css - jq有無現成函數改變rotateX/Y的deg10. javascript - QWebEngineView 如何爬 angular 的動態數據?
排行榜
 網公網安備
網公網安備