文章詳情頁
網頁爬蟲 - Python爬蟲返回狀態碼與實際情況不符?
瀏覽:217日期:2022-09-03 18:57:11
問題描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態碼是200。
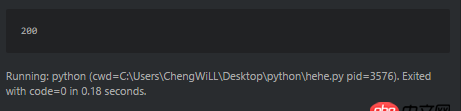
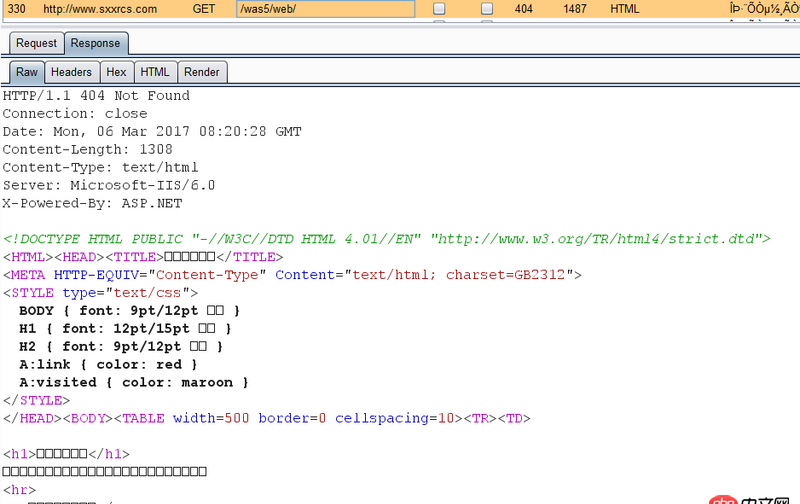
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應的也是404,請問這是為什么?
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關文章:
1. 點擊頁面就自動輸入到mysql.求解2. java - IDEA從SVN檢出項目 并在tomcat上運行 求詳細流程3. javascript - windos下第一次用Django無法正確創建工程目錄4. java - 多叉樹求值,程序高手,算法高手看過來5. node.js - 帶有node_modules目錄的項目,用phpstorm打開速度極慢,怎么解決?6. node.js - nodejs使用formidable上傳文件問題7. Laravel中文件上傳的問題8. 單擊登錄按鈕無反應9. 誰能告訴我php7+tp5.1時遇到使用session::set()問題10. 靜態資源文件引入無效
排行榜

 網公網安備
網公網安備