python - 如何用正則匹配出每一條記錄后面的字符串?
問題描述
實際的案例請看下面我想在通過正則語句匹配出每一條信息的最后部分
目地車站: [ 0112 ]獲取票價結果: iRet = 0TPU獲取單價結果, [ 0 ]TPU獲取單價為 [ 2.00 元] 票價最終單價為 [ 2.00 元] 票價
最后一段字符串前面都是[XXX]或[XXXX]這樣的字符串,當然 這個X是0-9的數字,每一行結束都有一個換行符,請各位幫幫我看看這個正則要怎么寫呢?
$DEBUG 2014-06-24 17:17:34.555@00000000@0000@[InitUITicketSinglePriceInfo][562]目地車站: [ 0112 ]$DEBUG 2014-06-24 17:17:34.565@00000000@0000@CTpuApp.GetTpuTicketPrice()-[1379]獲取票價結果: iRet = 0$DEBUG 2014-06-24 17:17:34.565@00000000@0000@[GetTicketSinglePrice][609]TPU獲取單價結果, [ 0 ]$DEBUG 2014-06-24 17:17:34.565@00000000@0000@[GetTicketSinglePrice][610]TPU獲取單價為 [ 2.00 元] 票價$DEBUG 2014-06-24 17:17:34.565@00000000@0000@[InitUITicketSinglePriceInfo][568]最終單價為 [ 2.00 元] 票價
問題解答
回答1:[d+](.+)
用.net測了一下,OK的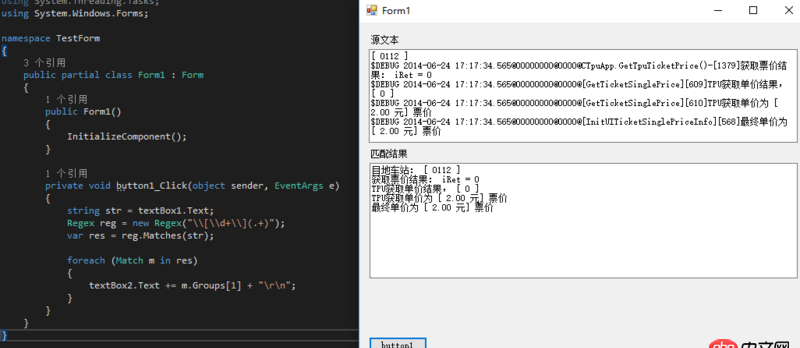
for match in re.finditer(r'[[0-9]+](.+)', '字符串'): # match start: match.start() # match end (exclusive): match.end() # matched text: match.group()
相關文章:
 網公網安備
網公網安備