文章詳情頁
python - 標簽樹的下行遍歷如何跳過第一個標簽
瀏覽:127日期:2022-08-08 11:07:17
問題描述
爬取網頁用下行遍歷的找出了我要的標簽,但第一個的內容我是不要的用.children好像無法跳出第一個標簽
for tr in soup.find(id='endText').children: if tr.string is not None:a = tr.string
網頁的內容:
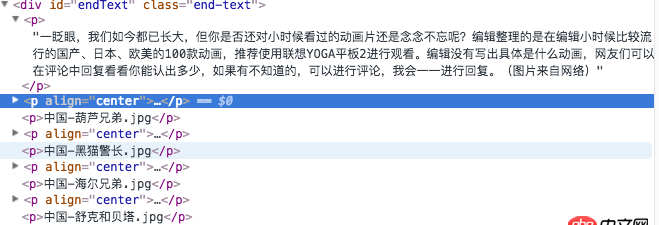 原鏈接:http://digi.163.com/14/1115/0...
原鏈接:http://digi.163.com/14/1115/0...
問題解答
回答1:p_list = list(soup.find(id='endText').find_all(’p’))for p in p_list[1:]: text = p.get_text() img = p.find('img') if img:print img.get(’src’) if text:print text
相關文章:
1. 關于docker下的nginx壓力測試2. css3 - 這個右下角折角用css怎么畫出來?3. debian - docker依賴的aufs-tools源碼哪里可以找到啊?4. javascript - 一個關于客戶端和前端通信的疑惑?5. javascript - webpack熱加載配置不生效6. java - 根據月份查詢多個表里的內容怎么實現好?7. javascript - 在 model里定義的 引用表模型時,model為undefined。8. css3 - 沒明白盒子的height隨width的變化這段css是怎樣實現的?9. python3.x - c++調用python310. android - 課程表點擊后浮動后邊透明可以左右滑動的界面是什么?
排行榜
 網公網安備
網公網安備