文章詳情頁
python - scrapy運行爬蟲一打開就關(guān)閉了沒有爬取到數(shù)據(jù)是什么原因
瀏覽:82日期:2022-08-05 15:09:38
問題描述
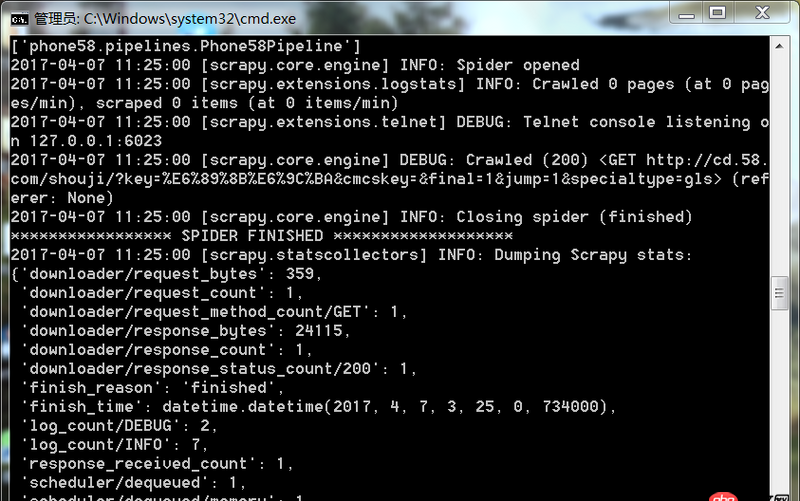
爬蟲運行遇到如此問題要怎么解決
問題解答
回答1:很可能是你的爬取規(guī)則出錯,也就是說你的spider代碼里面的xpath(或者其他解析工具)的規(guī)則錯誤。導致沒爬取到。你可以把網(wǎng)址print出來,看看是不是[]
相關(guān)文章:
1. windows2003下的apache響應時間特別長?2. 關(guān)于docker下的nginx壓力測試3. debian - docker依賴的aufs-tools源碼哪里可以找到啊?4. node.js - nodejs+express+vue5. javascript - vue vue-router 報$router重復定義6. 關(guān)于Java引用傳遞的一個困惑?7. java - 根據(jù)月份查詢多個表里的內(nèi)容怎么實現(xiàn)好?8. android - 復雜布局問題9. javascript - webpack熱加載配置不生效10. mysql - eclispe無法打開數(shù)據(jù)庫連接
排行榜
熱門標簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備