文章詳情頁
python - 使用scrapy框架爬百度圖片被墻
瀏覽:110日期:2022-06-30 14:19:37
問題描述
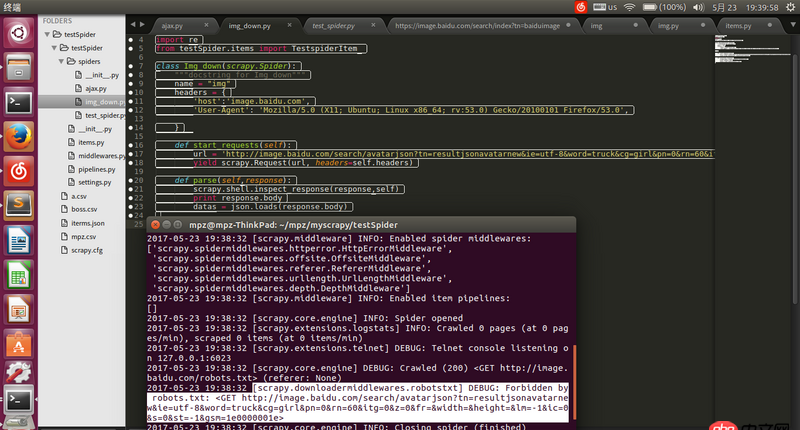
請求地址url是通過firefox查看得到的json的地址,用瀏覽器可以打開,但是用scrapy爬的時候就被ban了求解決辦法。
https://image.baidu.com/searc...
問題解答
回答1:在 settings.py 將 ROBOTSTXT_OBEY = False 試試。
回答2:不要加hearders試試
回答3:贊成樓上,如果還會被墻。可采用scrapy+selenium+phantomjs的方式。
相關文章:
1. docker - 如何修改運行中容器的配置2. python3.x - python連oanda的模擬交易api獲取json問題第五問3. nignx - docker內nginx 80端口被占用4. docker-machine添加一個已有的docker主機問題5. html5 - 百度echart官網下載的地圖json數據亂碼6. java - SSH框架中寫分頁時service層中不能注入分頁類7. node.js - 我是一個做前端的,求教如何學習vue,node等js引擎?8. javascript - js代碼獲取驗證碼倒計時問題9. 關于docker下的nginx壓力測試10. 為什么我ping不通我的docker容器呢???
排行榜
 網公網安備
網公網安備